From Conditions to Custom Code: How We Built It

Every card program starts with simple rules. Decline purchases at gambling merchants. Cap daily spend at $1000. Block transactions from countries you don't operate in. These are easy to configure, easy to reason about, and they cover a lot of ground—until a client needs to decline only when today's spending is 3x the cardholder's typical daily average. That kind of logic can't be expressed as a set of conditions, no matter how many you chain together.
That's the kind of challenge our Rules Engine was built to address. Sitting at the center of Lithic's authorization platform, it's a WebAssembly-powered system that lets clients configure authorization logic directly within Lithic without building and maintaining their own high-availability webhook responder. We launched it with pre-built templates for common use cases like conditional blocks and velocity limits, backed by shadow mode testing and backtesting against historical transactions. Since launch, we've expanded it beyond card authorizations as a core component of Authorization Intelligence, Lithic's framework for programmable decisioning across the payment lifecycle, to include 3DS authentication, ACH transfers, and digital wallet tokenization.
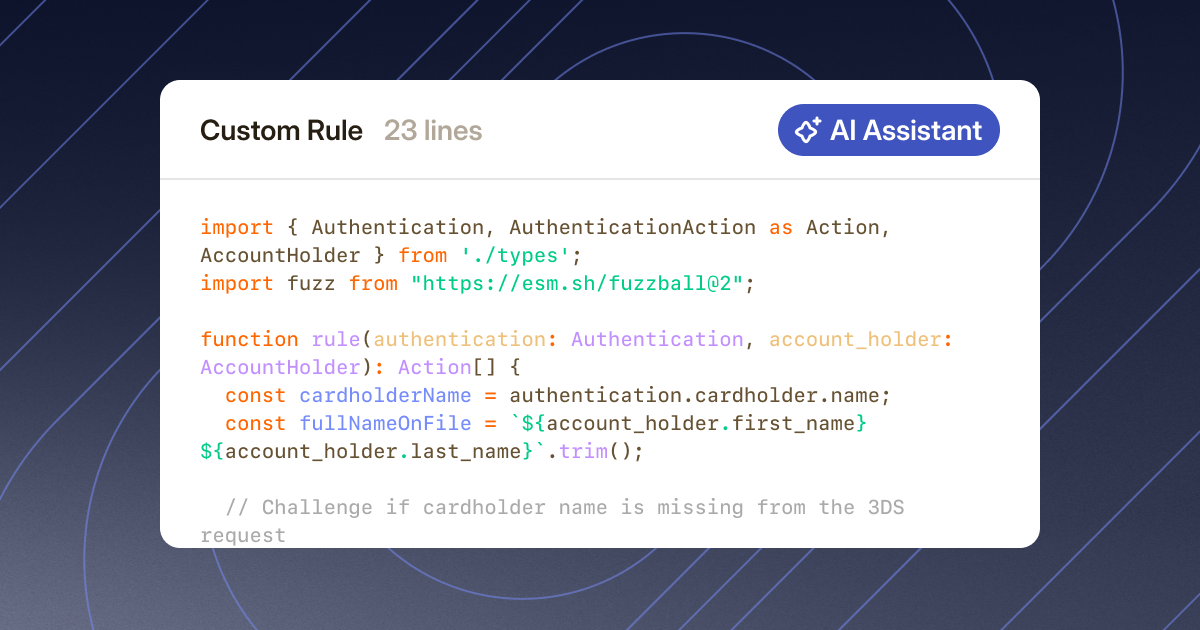
Templates can only take you so far. This post explains how we built Custom Code Rules, a recently released feature that’s part of our Fraud Command package which let clients write their own TypeScript logic directly Lithic's Rules Engine.
.png)
The need for expressiveness
We started with what all business rules engines support: conditional expressions. You specify a combination of conditions—transaction amount exceeds a threshold, merchant category is on a blocklist, card is being used in a foreign country—and we take the requested action if they're satisfied. It's easy to set up, easy to reason about, and works well for straightforward use cases.
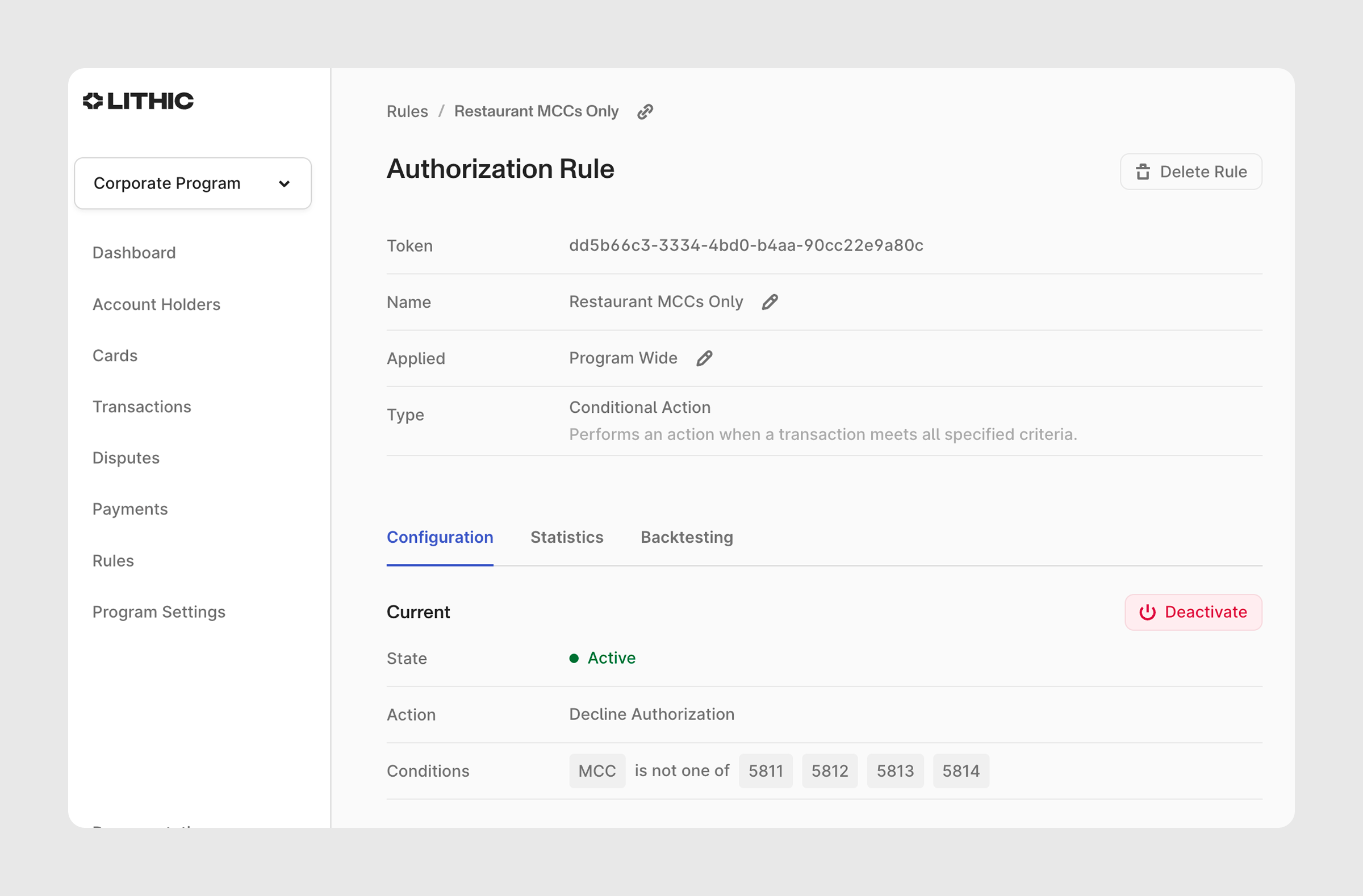
But real-world use cases are not always this straightforward. As our clients built more sophisticated card programs, we kept running into the limits of simple conditions:
- Relative thresholds: A velocity limit can enforce "24-hour spend does not exceeds $1,000," but what if you want to flag when a cardholder's transaction frequency in the last hour is 5x their typical hourly rate? That requires arithmetic on multiple features, not just a comparison against a static value
- Fuzzy matching: Merchants often use dynamic descriptors - "UBER *TRIP 1234" one day, "UBER *EATS 5678" the next. Grouping these requires string manipulation and pattern matching, not exact equality checks. Similarly, matching a billing address on a card-not-present (online or phone) transaction against what's on file needs fuzzy comparison to handle formatting differences
- Multi-factor risk scoring: Instead of a single condition, some programs want to assign risk points across multiple signals—foreign transaction (+2), unusually high amount (+3), new merchant (+2), no 3DS authentication (+3)—and decline when the cumulative score exceeds a threshold. This kind of scoring logic simply can't be expressed as AND/OR conditions
- Per-card behavior: A program managing cards for different employee tiers or departments may want different rules based on card metadata, without creating and maintaining a separate rule for each card. Or they may want to customize risk rules based on previous spending patterns
To understand how we approached this, it helps to look at the core model behind our Rules Engine. At a high level, Lithic's platform processes events (an authorization request, a 3DS challenge, a tokenization attempt) and maintains state (card attributes, account balances, spend history). We extract both into a set of input features for each rule evaluation. Based on those features, the rule produces actions: approve, decline, challenge, adjust some custom state, or more nuanced responses.
.png)
Expressiveness improves when we improve any part of this pipeline:
- Event features: The richer the data we expose from each event, the more precise rules can be. We surface everything from network risk scores to merchant details to 3DS authentication results
- Lithic state: Aggregated data like spend velocity, transaction counts, and historical patterns. We're continuously expanding what's available here
- Customer state: Client-provided data stored on Lithic resources, such as metadata tags on cards or accounts that encode business-specific attributes like employee level or risk tier
- Rule logic: The expressiveness of what the rule itself can compute
All the parts matter for the overall product. But investing in richer features (1-3) only goes so far if rule logic is limited to simple conditions that can't fully leverage them. We needed to give clients the full expressiveness of a real programming language, which meant choosing a language and figuring out how to run it safely on a payments hot path.
Why TypeScript
The typical answer to "we need more expressive rules" is a custom DSL, a purpose-built mini-language designed specifically for writing rules. But nobody wants to learn a bespoke language and its edge cases: not developers, not risk analysts, and not the AI agents that are increasingly writing rule logic on behalf of both. We built our Rules Engine on WebAssembly from the start. As Shopify Functions has also demonstrated, it's a proven approach for running user-defined logic in a sandboxed environment, and it let us keep the door open for arbitrary logic while maintaining deterministic execution for backtesting.
When it came to choosing a language for client-facing rules, we landed on TypeScript. Our internal rules are written in Rust, but for an external interface, TypeScript hits a sweet spot: it's one of the most widely used languages, has a rich library and tooling ecosystem, and its type system integrates naturally into our Dashboard with real-time validation and error feedback.
Clients aren't limited to what we ship out of the box. They can import any open-source library from the broader TypeScript ecosystem—for math operations, string matching, date conversions, or anything else—using URL imports from CDN providers like esm.sh. We handle the bundling and building behind the scenes. For example, a rule that needs to make timezone-aware decisions can import a date library inline:
import { toZonedTime } from 'https://esm.sh/date-fns-tz@3';
import { getDay, getHours } from 'https://esm.sh/date-fns@4';
function isHappyHour(timestamp: string): boolean {
const zonedDate = toZonedTime(timestamp, 'America/New_York');
const isFriday = getDay(zonedDate) === 5;
const hour = getHours(zonedDate);
return isFriday && hour >= 15 && hour < 22;
}This kind of logic—only allowing transactions during Friday happy hour in a specific timezone—would be cumbersome to express with conditional templates.
Built for AI agents
Does Custom Code mean our clients need to be engineers? Not at all. TypeScript turns out to be an excellent target language for AI-assisted rule authoring. LLMs have been trained on massive amounts of TypeScript code and our typed feature interface gives the model a clear contract. It knows exactly what inputs are available and what types they carry, which dramatically reduces hallucination and produces rules that compile on the first attempt.
In practice, the workflow looks like this: a risk analyst describes the rule they want in plain English, our AI assistant generates the TypeScript implementation, and the analyst reviews it in our Dashboard—not to audit the code line-by-line, but to verify the intent is captured correctly. From there, the rule goes into shadow mode, gets backtested against historical transactions, and only goes live once the analyst is satisfied with the results. The same testing and safety infrastructure that protects hand-written rules applies identically to AI-generated ones.

This matters because it decouples the sophistication of your authorization logic from the technical depth of the person defining it. A risk analyst who can articulate "decline card-not-present transactions over $500 from merchants we haven't seen before, unless the cardholder has completed 3DS authentication in the last 24 hours" now has a direct path to production-grade rule logic without filing a ticket with engineering and without learning to code.
Deterministic by design
Whether written by hand or generated by AI, every rule decision needs to be explainable and reproducible. With template-based rules, that's trivial: we can point to exactly which condition matched. With arbitrary programs, you'd typically need to capture an execution trace to understand why the system made the decision it did.
We chose a different tradeoff. Instead of tracing execution, we make the execution fully deterministic and reproducible:
- Every rule declares what features it needs from our list of available features. Features include event attributes (merchant category code, amount, merchant details - varying by event stream), card or account attributes, historical aggregations like spend velocity, or customer-provided state
- Before execution begins, we evaluate all requested features and collect them into a single input bundle
- Features are the only input to the rule. There are no side channels. If the rule needs the current time, it reads the event timestamp from a feature. If it calls a random number generator, it gets a deterministic PRNG seeded with the event hash
- We store all evaluated features alongside rule results for auditing
The practical implication: rules cannot make external calls, conditionally load state, or generate true random numbers. In exchange, we can reproduce any execution exactly: load the stored features from our data warehouse and re-run the rule with identical results. This is what powers backtesting for Custom Code rules: the same mechanism that lets us replay template-based rules against historical transactions works unchanged for arbitrary TypeScript logic.
This design also has a performance payoff. Since rules are purely computational (e.g., no I/O, no dynamic loads, all input features pre-computed) the biggest challenge isn't execution time but having the WASM module ready to run. Compiling WebAssembly to native code takes non-trivial time, so we pre-compile programs and cache the resulting native code across multiple layers: in-memory, on-disk, and in object storage. Once loaded, rule execution is capped at 15ms of CPU time, which in practice is plenty.
Security first
Running user-provided code inside Lithic’s infrastructure is a significant security decision. JavaScript sandboxing in particular has a track record of breakouts. Most recently, a critical vulnerability in the workflow automation platform n8n allowed executing arbitrary commands on the server through a sandbox escape, potentially leaking sensitive credentials. This is not an isolated incident; JS sandbox escapes are a recurring pattern across the industry.
We designed Custom Code with a defense-in-depth approach, where no single layer is the sole line of defense:
- Static analysis: We perform validation checks on the TypeScript program before it's ever compiled
- Compilation boundary: We compile TypeScript to WebAssembly ourselves - we don't accept arbitrary WASM uploads and have no plans to. This means customer code never runs as native JavaScript, and the only WASM that reaches our runtime is produced by our own trusted compiler pipeline
- WASM sandbox: The compiled module executes in a sandboxed environment powered by Wasmtime, a runtime with a strong security track record. All operating system interfaces are stubbed out during execution
- Infrastructure isolation: Execution runs on servers with minimal state and tightly scoped permissions. All executions are logged and monitored
These layers compound. Even a hypothetical Wasmtime sandbox escape would require crafting an exploit through compiled TypeScript, and even then, the attacker would land on an isolated server with no access to sensitive data.
Conclusion
With Custom Code, we've removed the ceiling on what clients can express in their rules. But looking back at the expressiveness model we outlined earlier (i.e., event features, Lithic state, customer state, and rule logic), Custom Code addresses the fourth axis. The rule logic is now as flexible as it can be. The question becomes: what data are you feeding into it?
That's where our focus shifts next. Authorization Intelligence is the broader vision—programmable, context-aware decisioning across your entire payment stack—and Custom Code unlocks the rule logic axis. Now we're investing in the other three: deeper event data with more granular signals from card networks and 3DS authentication, expanded Lithic state with advanced aggregations beyond simple velocity counters, and more powerful customer state with the ability to store and query metadata on Lithic resources. The more context rules can access, the more precisely they can act. Custom Code is now ready to take full advantage of it.
If you want to try Custom Code Rules, they're available today within our Fraud Command suite via API and the Lithic Dashboard. We'd love to hear what you build with them. And if this kind of problem excites you, we're hiring.